
Redgate SQL Provision, SQL Clone, Data Masker Part2
Table of Contents
A long time ago in a galaxy far, far away…
This post is over 24 months old, that is an lifetime in tech! Please be mindful of that when reading this post, young Padawan, as it could be outdated. I try to keep things up to date as much as possible. If you think something needs updating, please let me know in the comments.
Recap
In my first post on Redgate SQL Provision, I ran some basic tests against the AdventureWorksDW2017 database to demonstrate how SQL Provision works.
The headline was that I saved 47 seconds cloning a database in 2 seconds that took 49 seconds to provision, nothing to write home about. So to really prove how cool this product is, it needs to run against something much, much larger…if I still get the same sort of results, then that would be pretty cool.
The Stack Overflow Database
The Stack Overflow database is periodically published as an XML data dump and Brent Ozar uses it as part of performance tuning courses and so being the super helpful person they are, carves it up into several different sized backup files. What I find most helpful about this, is given that the structure is consistent it means I can test stuff out at speed against one of the smaller databases before unleashing it on one of the larger datasets. There are tonnes of versions available, but the ones I have used for this test can be found on this page.
The Stack Overflow database is periodically published as an XML data dump and Brent Ozar uses it as part of performance tuning courses and so being the super helpful person they are, carves it up into several different sized backup files. What I find most helpful about this, is given that the structure is consistent it means I can test stuff out at speed against one of the smaller databases before unleashing it on one of the larger datasets. There are tonnes of versions available, but the ones I have used for this test can be found on this page.
So the idea is to evaluate against StackOverflow2010 database and run some preliminary tests against that. I would then duplicate the masking file, switch the database connection and run a full test against StackOverflow.
I have decided to mask a few columns within the User table to imitate masking a customer table. Here is a screenshot of the first 10 rows;

Setting up the masking rules
There is not a huge amount of columns to choose from, but we just need a few columns for the test because what we are interested in isn’t how quickly my machine can process a load of update statements, but how quickly it can complete an end to end process and make multiple copies available to my (imaginary) team. I chose to mask the following columns;
- AboutMe
- DisplayName
- Location
- WebsiteURL
There are 9,737,247 users in this dataset and that posed a problem with trying to provide each user a unique name. I didn’t really have to do this, but I figured I would keep it reasonably accurate. The predefined datasets weren’t really viable since none of them were going to provide enough unique values. There is less than a quarter of a million words in the English dictionary #gofigure, there is nowhere near enough person names, so I had to configure UserName differently.
So the first masking step covered AboutMe, Location, WebsiteURL with some basic substitution. I set the AboutMe column to produce some random words up to a max of 50 characters;
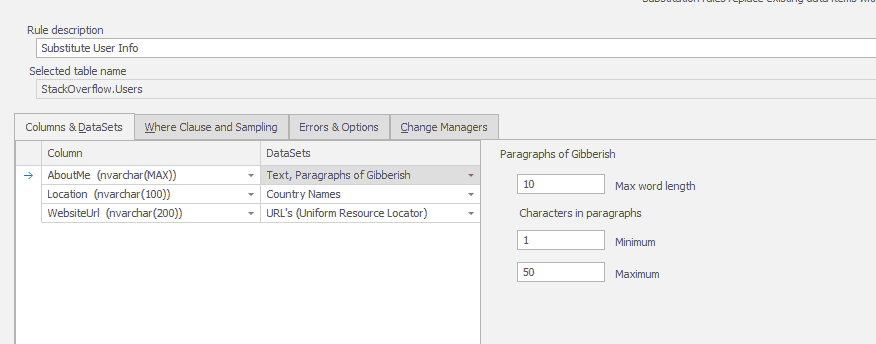
I applied a predefined list of country names to the location column;

And I configured the generation of random URLs as shown below;

For the user name, there is a large selection of options from scrambling to regular expressions, but I opted for a custom calculation based on the user ID since the user ID is unique. So I went for this;
'User\_' + RIGHT('0000000000' + CAST(ID AS VARCHAR),10)
Which will result in a consistent pattern of “User_” followed by 10 digits consisting of the User ID plus some leading zeros. So ID 1 will be User_0000000001, ID 9999 will be User_0000009999 and so on. That kinda fits nice with my OCD then as they’ll all be a consistent length. So the rule looks like this;

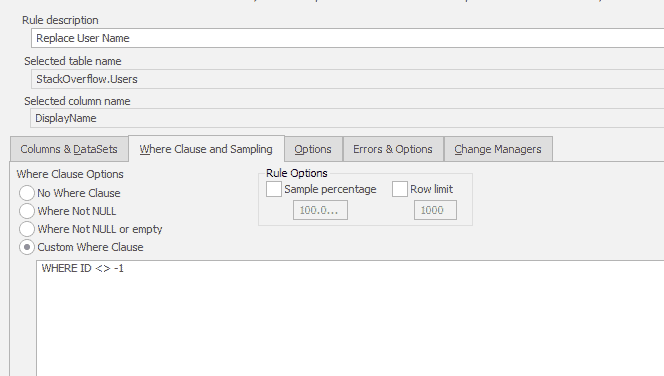
But for good measure I excluded the bot (which has an ID of -1) from the rule because User_00000000-1 just wouldn’t look right. You can apply filters on the WHERE clause tab;
Building an image
I ran tests against the 2010, 2013 and the full dataset, below is a walkthrough of the full dataset…
To build an image, I need a backup file or an existing database and a file share for the image to be hosted. I then wrote a Powershell script to build the image which looks like this;
Connect-SqlClone -ServerUrl 'http://localhost:14145'
$SqlServerInstance = Get-SqlCloneSqlServerInstance -MachineName DESKTOP-H4M4K2E -InstanceName "" \`
$imageDestination = Get-SqlCloneImageLocation -Path 'DESKTOP-H4M4K2EImage'
$imageName = "StackOverflow"
$myMaskingModification = New-SqlCloneMask -Path 'C:Codedemos-redgate-sql-provisionstackoverflowstackoverflow.dmsmaskset'
$imageOperation = New-SqlCloneImage -Name $imageName -SqlServerInstance $sqlServerInstance -BackupFileName @('G:BackupsStackOverflow.bak') -Destination $imageDestination -Modifications $myMaskingModification
$imageOperation | Wait-SqlCloneOperation
This process will initially build an image, then mask four columns in two steps for just under 10 million rows. I have cut down the output of the log to the salient points;
14:33:42 Operation started
15:10:04 Attach database
15:10:04 Starting Data Masking Script
15:38:44 Finished Data Masking Script
15:39:21 Operation succeeded with a duration of 01:05:39
It restored the database in ~37 minutes, with masking taking ~28 minutes. Final footprint of the image on disk is ~329GB. The original database was ~323GB.
Send in the clones
So this is where SQL Provision really comes into its own. I set up a Powershell script to imitate provisioning databases for 10 developers, 3 test databases and 1 pre prod database. The Powershell script looks like this;
Connect-SqlClone -ServerUrl 'http://localhost:14145'
$SqlServerInstance = Get-SqlCloneSqlServerInstance -MachineName DESKTOP-H4M4K2E -InstanceName "" \`
$imageName = "StackOverflow"
$image = Get-SqlCloneImage -Name $imageName
$image | New-SqlClone -Name 'StackOverflow\_clone\_Developer001' -Location $sqlServerInstance | Wait-SqlCloneOperation
$image | New-SqlClone -Name 'StackOverflow\_clone\_Developer002' -Location $sqlServerInstance | Wait-SqlCloneOperation
$image | New-SqlClone -Name 'StackOverflow\_clone\_Developer003' -Location $sqlServerInstance | Wait-SqlCloneOperation
$image | New-SqlClone -Name 'StackOverflow\_clone\_Developer004' -Location $sqlServerInstance | Wait-SqlCloneOperation
$image | New-SqlClone -Name 'StackOverflow\_clone\_Developer005' -Location $sqlServerInstance | Wait-SqlCloneOperation
$image | New-SqlClone -Name 'StackOverflow\_clone\_Developer006' -Location $sqlServerInstance | Wait-SqlCloneOperation
$image | New-SqlClone -Name 'StackOverflow\_clone\_Developer007' -Location $sqlServerInstance | Wait-SqlCloneOperation
$image | New-SqlClone -Name 'StackOverflow\_clone\_Developer008' -Location $sqlServerInstance | Wait-SqlCloneOperation
$image | New-SqlClone -Name 'StackOverflow\_clone\_Developer009' -Location $sqlServerInstance | Wait-SqlCloneOperation
$image | New-SqlClone -Name 'StackOverflow\_clone\_Developer010' -Location $sqlServerInstance | Wait-SqlCloneOperation
$image | New-SqlClone -Name 'StackOverflow\_clone\_Test001' -Location $sqlServerInstance | Wait-SqlCloneOperation
$image | New-SqlClone -Name 'StackOverflow\_clone\_Test002' -Location $sqlServerInstance | Wait-SqlCloneOperation
$image | New-SqlClone -Name 'StackOverflow\_clone\_Test003' -Location $sqlServerInstance | Wait-SqlCloneOperation
$image | New-SqlClone -Name 'StackOverflow\_clone\_PreProd' -Location $sqlServerInstance | Wait-SqlCloneOperation
Each clone build is a separate command, so there is no end to end log and I don’t have the patience to collate them for this post! Here is the output from one clone build;
20:13:40 Operation started
20:13:44 Started to attach database StackOverflow\_clone\_Developer001
20:13:45 Finished to attach database StackOverflow\_clone\_Developer001
20:13:45 Operation succeeded with a duration of 00:00:04.588
In under 5 seconds it provisioned a dedicated database! In total the process took just over a minute to complete with a footprint of ~640MB for all 14 databases;
I can now apply changes directly to a single database independent from the rest of my team;
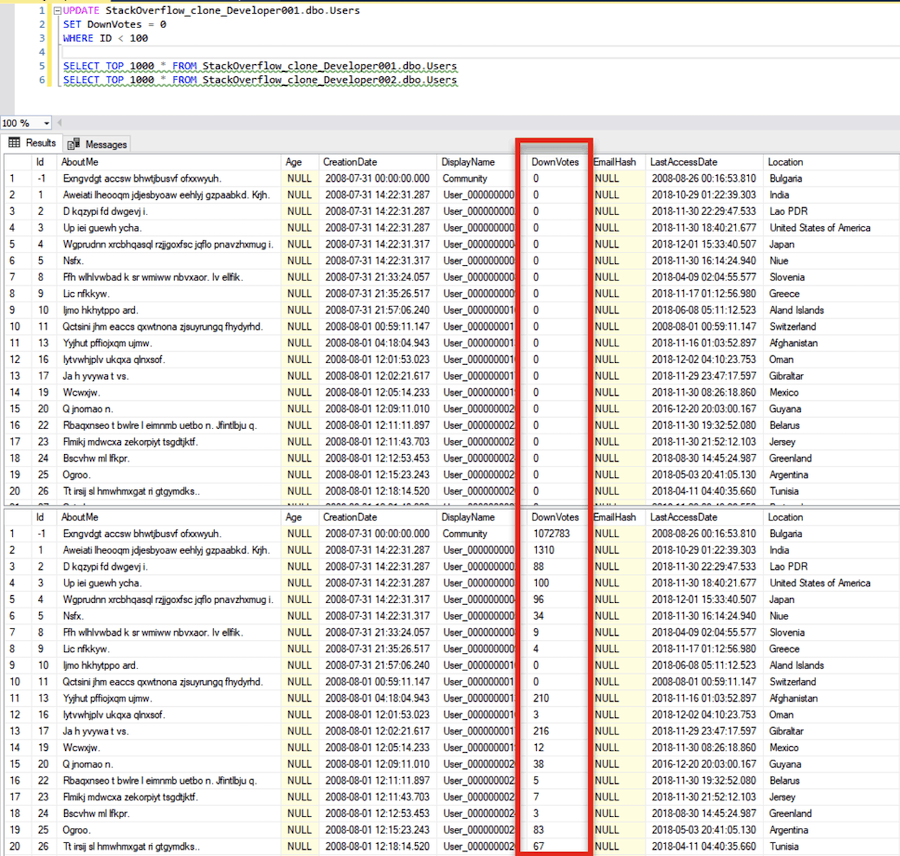
In the screenshot above, you can see that I have updated the user database for Developer001. When I run a query against Developer001 and Developer002 you can see that all information is returned consistently except for the changes applied to Developer001.
Result
This test is a bit more like it! I have provisioned a 300GB database and securely masked and provisioned independent copies of it for 10 developers, three test tracks and pre prod testing in under 70 minutes! As more changes are applied to these clones, their footprint will increase, but when a developer can be given the ability to drop their clone and re-create it in seconds or even create more copies, this tool adds so much flexibility to development teams!
Here is the stats from each load;
Footprint
| Database | Database Size | Image Size | Clone Size |
|---|---|---|---|
| 2010 | ~9GB | ~9GB | 616MB |
| 2013 | ~51GB | ~48GB | 616MB |
| Full | ~323GB | ~329GB | 616MB |
Timings
| Database | Time to build image | Time to create clones |
|---|---|---|
| 2010 | 00:02:19 | 00:01:01 |
| 2013 | 00:14:35 | 00:00:53 |
| Full | 01:11:39 | 00:01:04 |
Note, reading this back whilst moving it, I am disputing the size of the clones! Once I have had time to clean up the new site I will re-read this properly. My immediate reaction is I believe the clones should be smaller!
Summary
All in all, I am really impressed with this process, it is possible to securely run this since the backup can be hosted on a restricted file share, whilst the image is being constructed it is only accessible to the service account and once complete, developers can only obtain a clone of the de-sensitised image.
Next steps
There are changes I could make to the masking process to optimise the image load time. There are tips and techniques covered in the Redgate University videos, but since the main test was around how quickly I could spin up multiple copies of the database I didn’t spend a huge amount of time doing this. All scripts used for the blog post can be found on Github.
Further reading
You can find more information on the SQL Provision product page and Redgate have set up some useful videos at the Redgate University.

#mtfbwy